


We've been building agents that investigate production incidents for the past couple of years. Our agents at Deductive query Datadog, pull Splunk logs, trace through service dependencies, and try to figure out why something broke. And one thing that has become painfully obvious over this time is that the infrastructure these agents are reading from was never designed for them.
Every time one of our agents investigates an incident, it fights the same battle: make a metrics query, wait, make a logs query to a different system, wait, pull traces from yet another store, wait, and then try to stitch the story together. The backends are fast at serving each individual query because they were built for a human refreshing a dashboard. But the agent doesn't need any individual query to be fast. It needs the whole investigation to be coherent.
This got us thinking about what observability storage would look like if we designed it from scratch for an agentic world. Not as an incremental improvement, but as a fundamental rethinking of the tradeoffs. What follows is a mix of things we've learned the hard way and ideas we think are worth exploring.
The Assumption Baked Into Every Observability Backend
Every major observability platform today (Datadog, Splunk, New Relic, Grafana) was architected around a single assumption: a human operator is the consumer. This assumption runs deep, shaping how data is indexed, how queries are optimized, how storage is tiered, and how compression is applied. Sub-millisecond latency on dashboards, arbitrary dimensional slicing, and interactive drill-downs are all features optimized for a person staring at a screen at 2am during an incident.
But the consumer is changing. Agentic systems are already investigating incidents, correlating signals across services, and performing root cause analysis, and the mismatch between what these agents need and what current backends provide is becoming increasingly clear. We believe the industry needs to rethink observability storage from first principles, and in this post we want to walk through the key shifts we see, grounding each in both our practical experience and relevant database research.
Shift 1: Throughput Over Latency
How We Got Here
Traditional observability backends are optimized for interactive latency. When a human clicks a dashboard widget, they expect results in under 100ms, which drives architectural decisions like:
- Pre-aggregated rollups at multiple time granularities
- In-memory caching layers (e.g., Redis, Memcached) for hot data
- Inverted indexes optimized for point lookups
- Columnar stores with sort keys tuned for time-range queries
Datadog, for example, uses a custom time-series database (Husky) that pre-computes rollups at 1s, 10s, 60s, and 300s intervals, which is expensive to maintain but enables sub-second dashboard rendering. This is exactly the right design choice when a human is the consumer.
What Changes With Agents
Agents don't care if a query takes 500ms instead of 50ms, because they're already waiting on LLM inference calls that take 1-10 seconds. The bottleneck in an agentic pipeline is never storage read latency; it's the reasoning step.
We've watched our agents spend 8-10 seconds on an LLM call to reason about a set of metrics, and then 40ms fetching the next batch of data. The ratio is absurd. We're optimizing the wrong thing.
This means you can trade latency for throughput. Instead of maintaining expensive pre-aggregated rollups, you can store raw data and compute aggregations on read, and instead of keeping hot data in memory, you can let the agent batch its reads and stream through compressed data sequentially.
1# Current model: optimized for latency
2# Pre-aggregated at write time, fast point lookups
3GET /api/v1/query?metric=cpu.usage&from=now-1h&rollup=avg:60s
4# Response: 60 pre-computed points, <50ms
5
6# Agent model: optimized for throughput
7# Raw data, batch scan, compute on read
8SCAN /signals/service:payments/2024-01-15T00:00..2024-01-15T01:00
9# Response: 3600 raw points + associated logs + trace spans
10# Latency: 200-500ms, but the agent doesn't care
The economic implications are significant: pre-aggregation is one of the most expensive operations in observability pipelines, consuming compute at write time, requiring multiple storage tiers, and losing fidelity in the process. An agent-native backend can skip all of this.
Shift 2: Compression Economics Flip
The Current Tension
Observability platforms face a fundamental tension: aggressive compression saves storage costs but increases read latency. Since humans need interactive response times, most systems settle for moderate compression that is sufficient to reduce storage bills but not so aggressive that decompression becomes noticeable.
Prometheus, for example, uses Gorilla compression (Pelkonen et al., 2015), an XOR-based delta encoding scheme for time series that achieves roughly 1.37 bytes per sample. This works well, but it's optimized for fast decompression rather than maximum compression ratio.
Agents Hide the Decompression Cost
The key insight is that in an agentic pipeline, LLM inference calls dominate wall-clock time. A typical agent loop looks like:
1while not resolved:
2 context = query_observability_data() # 200-500ms
3 reasoning = llm_call(context) # 2,000-10,000ms
4 action = parse_and_execute(reasoning) # 50-200ms
The query_observability_data() step accounts for at most 5-10% of the loop time, which means you can afford to spend significantly more CPU on decompression. Algorithms like Zstandard at high compression levels, Brotli, or even domain-specific compression schemes all become viable because the decompression latency is effectively hidden behind the LLM call.
Consider the numbers:
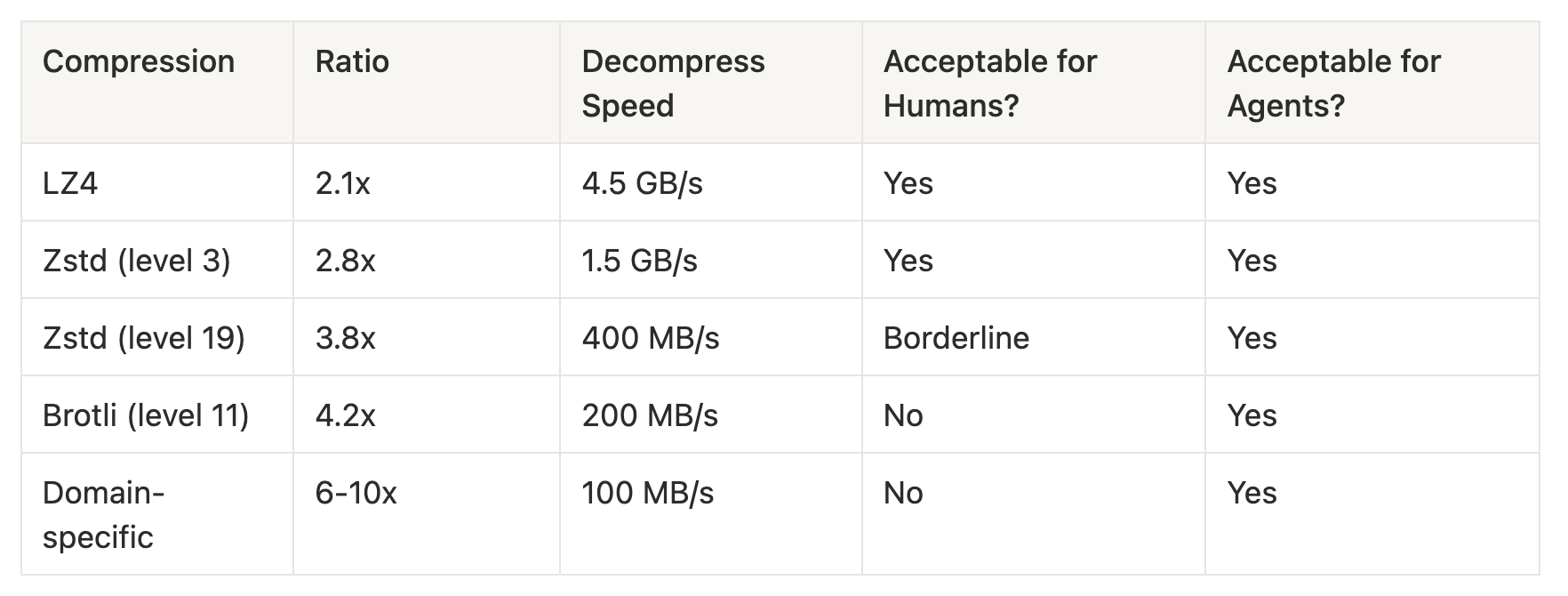
With domain-specific compression that exploits the repetitive structure of metrics names, log templates, and trace schemas, you could achieve 6-10x compression ratios. For a platform ingesting 100TB/day, that's the difference between 3PB and 500TB of monthly storage, which at cloud storage prices represents a massive cost reduction.
Shift 3: Semantic Coherence Over Dimensional Flexibility
The Dimensional Model and Why It Exists
Current observability backends are built around dimensional data models where metrics have tags, logs have fields, and traces have attributes, allowing you to slice and dice along any dimension: service:payments AND env:prod AND region:us-east-1.
This is powerful for exploration because a human doesn't always know what they're looking for and needs the freedom to pivot, filter, and drill down in arbitrary directions. When you're debugging at 2am and you're not sure if the problem is in the payments service or the database or the load balancer, dimensional flexibility is essential.
Agents Don't Explore; They Investigate
Agents have a fundamentally different access pattern: rather than exploring, they're following causal chains. We've watched hundreds of thousands of agent investigations at this point, and the access patterns are remarkably consistent:
- Start with an alert: "Error rate spike on
payments-service" - Pull metrics for
payments-service(latency, error rate, throughput) - Correlate with upstream dependencies to identify what changed
- Pull traces that show the error path
- Extract relevant log lines from those traces
- Check deployment events, config changes, and infrastructure metrics
This is a graph traversal, not a dimensional query. The agent starts at a node (the alert) and walks outward through dependencies, correlating signals along the way.
Current backends make this expensive because the agent has to query the metrics store for service metrics, query a separate trace store for correlated traces, query a separate log store for associated logs, query yet another store for deployment events, and then reconstruct relationships manually. That's 4-5 separate queries across different storage engines, with the agent doing all the correlation work. We spend a surprising amount of our engineering effort just stitching data together that, conceptually, belongs together.
A Semantically Coherent Storage Model
What if storage was organized around investigation contexts rather than signal types? Imagine a format where related signals are co-located:
1InvestigationBlock {
2 entity: "payments-service"
3 time_range: [2024-01-15T00:00, 2024-01-15T01:00]
4
5 metrics: {
6 cpu_usage: CompressedTimeSeries(...)
7 error_rate: CompressedTimeSeries(...)
8 latency_p99: CompressedTimeSeries(...)
9 }
10
11 traces: [
12 { trace_id: "abc", spans: [...], linked_logs: ["log_1", "log_5"] }
13 ]
14
15 logs: [
16 { id: "log_1", message: "Connection refused...", linked_trace: "abc" }
17 ]
18
19 events: [
20 { type: "deployment", version: "v2.3.1", timestamp: ... }
21 ]
22
23 dependencies: [
24 { upstream: "api-gateway", downstream: "payments-db" }
25 ]
26}
This is inspired by how document databases like MongoDB store related data together for read efficiency, but applied to observability. Instead of normalizing across signal types, you denormalize around entities and time windows, so the agent can make one read to get everything it needs for a given service in a given time window, including the dependency graph that tells it where to look next.
Shift 4: Self-Optimizing Storage
This is the shift we're most excited about, because database research offers a rich body of work on systems that adapt their physical layout based on workload patterns, and the agentic context makes these ideas significantly more practical.
Adaptive Indexing
Database Cracking (Idreos, Kersten & Manegold, CIDR 2007) introduced the idea of incrementally building indexes as a side effect of query processing: instead of pre-building indexes on all possible dimensions, the system reorganizes data partitions each time a query touches them.
Applied to observability, an agent-native backend could start with a basic time-partitioned layout and progressively reorganize data based on which services, time ranges, and signal correlations agents actually query. After seeing repeated queries correlating payments-service metrics with payments-db logs, the system would co-locate that data automatically. The storage literally learns the topology of your system from the way agents investigate it.
Learned Index Structures
The Learned Index paper (Kraska et al., 2018) demonstrated that ML models can replace traditional B-trees and hash indexes, predicting data locations with lower memory overhead and comparable speed. For observability data, you could train lightweight models that predict where relevant signals cluster for a given incident type, which services are likely to be queried together based on dependency topology, and what the optimal compression strategies are per data segment based on access patterns.
1# Conceptual: a learned index for observability data
2class AgentAwareIndex:
3 def __init__(self):
4 self.access_model = LightweightNN() # Predicts access patterns
5 self.layout_optimizer = LayoutPlanner()
6
7 def on_query(self, query_context):
8 """Learn from every agent query"""
9 self.access_model.update(query_context)
10
11 if self.should_reorganize():
12 new_layout = self.layout_optimizer.plan(
13 current_layout=self.layout,
14 predicted_patterns=self.access_model.predict_next()
15 )
16 self.background_reorganize(new_layout)
17
18 def locate(self, entity, time_range, signal_types):
19 """Use learned model to find data efficiently"""
20 predicted_blocks = self.access_model.predict_location(
21 entity, time_range, signal_types
22 )
23 return self.fetch_blocks(predicted_blocks)
Workload-Driven Physical Design
Systems like AutoAdmin (Chaudhuri & Narasayya, VLDB 1997) and more recently Bao (Marcus et al., SIGMOD 2021) use workload analysis to automatically tune physical storage layout by deciding on partitioning schemes, sort orders, and materialized views. For an agent-native backend, this translates to automatic co-location of services frequently queried together, adaptive compression where rarely accessed segments get compressed more aggressively while hot segments use lighter compression, dynamic denormalization that pre-joins metrics with traces when agents repeatedly request them together, and predictive prefetching based on the agent's current investigation path.
The reason this is more practical in an agentic context than in a traditional database context is that agents generate a much cleaner workload signal than humans. Human queries are noisy because people explore, change their minds, and run ad-hoc queries, whereas agent queries are systematic and repeatable, making workload prediction significantly more tractable. When our agents investigate a database latency issue, they follow roughly the same investigation pattern every time. That predictability is a gift to a self-optimizing storage system.
The Open Format Question
This brings me to perhaps the most provocative question: could an open-source format replace proprietary observability backends entirely for agent workloads?
Consider what Apache Parquet did for analytics. Before Parquet, data was locked in proprietary formats tied to specific query engines, and Parquet created a universal columnar format that any engine could read (Spark, Presto, DuckDB, Polars), effectively decoupling storage from compute and fundamentally changing the economics of data platforms.
Observability hasn't had its Parquet moment yet. Data remains locked in Datadog's proprietary storage, Splunk's indexes, and Elastic's shards, with each vendor maintaining its own format, its own query language, and its own retention policies. An agent-native observability format could change this. Imagine an open spec, call it something like OASF (Open Agent-native Signal Format), that defines:
- A self-describing schema for observability signals (metrics, logs, traces, events) with embedded relationship metadata
- A columnar layout optimized for sequential scan and batch decompression rather than point lookups
- Embedded dependency graphs so agents can traverse service relationships without a separate CMDB query
- Pluggable compression with support for domain-specific codecs tuned for observability data patterns
- Metadata layers that enable self-optimization: access statistics, co-location hints, and learned index checkpoints
This format could sit on cheap object storage (S3, GCS) and be queried directly by agents, requiring no database server and no proprietary query engine.
1# Hypothetical: querying an OASF file directly
2import oasf
3
4# Open a signal file from S3
5signals = oasf.open("s3://observability/payments-service/2024-01-15.oasf")
6
7# Get correlated signals: metrics, logs, traces together
8context = signals.investigation_context(
9 entity="payments-service",
10 time_range=("2024-01-15T00:00", "2024-01-15T01:00"),
11 include_dependencies=True,
12 depth=2 # Two hops in the dependency graph
13)
14
15# Feed directly to an agent
16agent.investigate(context)
The economic implications are significant: if observability data lives in an open format on object storage, the cost drops from $15-25/GB/month (typical SaaS observability pricing) to $0.02/GB/month (S3 standard), and even accounting for compute costs for decompression and querying, that's an order-of-magnitude reduction.
Open Questions
We want to be honest that this is a space with more questions than answers right now, and a few are worth exploring in particular.
How do you handle the write path? Current systems are optimized for high-throughput ingestion, and an agent-native format still needs to ingest data efficiently. You can't just dump everything into files and call it a day, because there's real engineering in the write path around buffering, partitioning, and making data available for query with reasonable freshness.
What about hybrid workloads? In practice, both humans and agents will be consuming observability data, which means the format either needs to serve both or you need an efficient translation layer between them. We don't think humans disappear from the loop; they just move up the stack.
Can self-optimization actually work at scale? Learned indexes and adaptive layouts are promising in research but have limited production deployments, and the observability domain has specific characteristics (append-only, time-ordered, high cardinality) that may make this more or less tractable.
Who builds this? An open format needs a community. OpenTelemetry solved the collection and instrumentation problem, so the natural question is whether a similar effort could solve the storage problem. We'd love to see this become a real project.
Conclusion
The shift from human-operated to agent-consumed observability is not incremental; it changes the fundamental design tradeoffs of storage systems across throughput, compression, semantic coherence, and self-optimizing layouts, and potentially introduces an open format that decouples observability storage from proprietary backends.
We're early in this transition, and most agent-based observability tools today (including ours) work on top of existing backends, paying the tax of architectures designed for a different consumer. The opportunity lies in building storage that's native to how agents actually work.
If you're thinking about this space, whether you're building agents, designing storage systems, or rethinking your observability stack, I'd love to hear your perspective. We're all figuring this out together, and I think the next generation of observability infrastructure will look very different from what we have today.
References
- Pelkonen, T., Franklin, S., Teller, J., et al. "Gorilla: A Fast, Scalable, In-Memory Time Series Database." VLDB, 2015.
- Idreos, S., Kersten, M. L., & Manegold, S. "Database Cracking." CIDR, 2007.
- Kraska, T., Beutel, A., Chi, E. H., Dean, J., & Polyzotis, N. "The Case for Learned Index Structures." SIGMOD, 2018.
- Chaudhuri, S. & Narasayya, V. R. "An Efficient Cost-Driven Index Selection Tool for Microsoft SQL Server." VLDB, 1997.
- Marcus, R., Negi, P., Mao, H., et al. "Bao: Making Learned Query Optimization Practical." SIGMOD, 2021.




