

.png)
TL;DR
Most teams running AI agents are flying blind - they open individual traces, poke around, and move on. But a single trace is just an anecdote. The real signal lives in the aggregate. We pointed Deductive AI at 100+ LangSmith runs from a production agent and found three antipatterns hiding in plain sight:
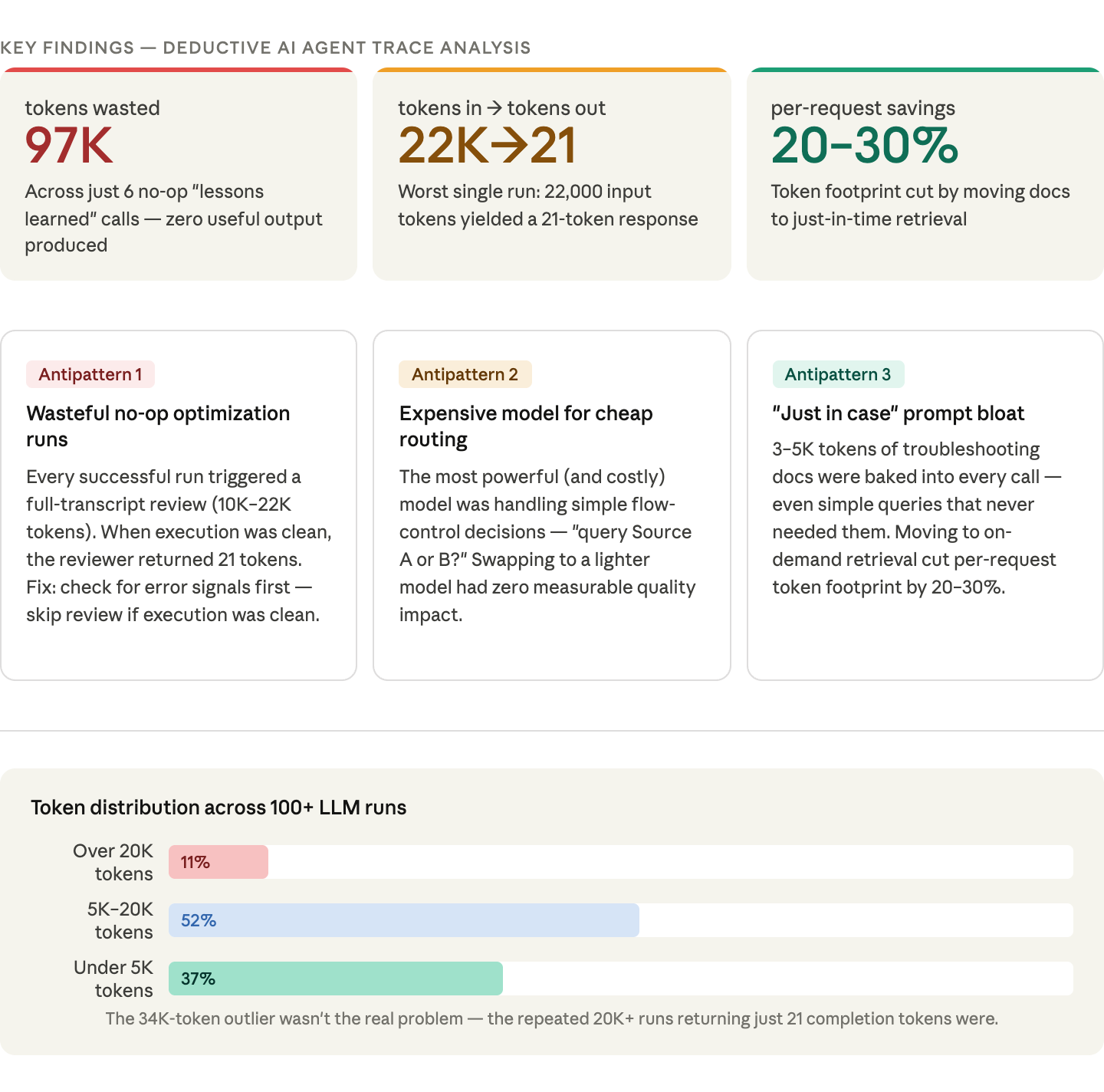
1. Wasteful no-op calls. A "lessons learned" reviewer was consuming 10K–22K tokens per run to return 21 tokens of output when execution was clean. Six such runs burned 97,000 tokens for zero useful output. Fix: add a cheap pre-check for error signals before triggering the review.
2. Overpowered routing. The most expensive model was handling simple flow-control decisions, "query Source A or B?" Swapping to a lighter model had zero quality impact and meaningfully cut cost per run.
3. Always-on documentation. 3–5K tokens of troubleshooting guides were baked into every prompt, whether or not the agent ever needed them. Moving to just-in-time retrieval cut per-request token footprint by 20–30%.
None of this was visible from a single trace. All of it became obvious when we looked across runs. If you're using LangSmith and wondering where your token budget is actually going - stop reading individual needles and start looking at the haystack.
Introduction
Most teams building AI agents have a visibility problem. You're spending real money on LLM calls, your LangSmith dashboard is filling up with traces, but you can't confidently answer basic questions about where your budget is actually going. Which calls are wasteful? Which prompts are bloated? Is that expensive run the norm or an outlier? You have hundreds of traces and gigabytes of span data, but there's no easy way to query across it.
We worked with a customer building production AI agents to find out what was actually hiding in their traces. We pointed Deductive AI at their LangSmith runs, aggregated across hundreds of executions, and let it do what it's good at: finding patterns in messy, semi-structured data at scale. Here's what we found.
Traces are Needles - We Need the Haystack
Traces are an extremely powerful but often misunderstood tool in the observability toolbox. Unlike metrics and logs, traces allow us to understand the full lifecycle of a request and understand the hidden relationships that only become evident when we stitch logs together. However, a trace is essentially just an anecdote, and while these anecdotes can be incredibly valuable in helping us develop hypotheses about our systems, drawing conclusions from anecdotal evidence is a dangerous game.
The modern systems observability world has solved this by aggregating traces, which gives us incredibly valuable insights about individual spans (is this function call actually a bottleneck in the majority of cases?) as well as high level patterns like service call graphs. Aggregation unlocks value beyond just anecdotes. But in the AI tracing world, the tooling hasn't caught up. Aggregating classic distributed traces is already complex, but when we consider the complexity of LLM traces that contain large, high-cardinality text artifacts like prompts, retrieved context, and variable human input, the problem becomes much harder. Throw in indeterminism, and the problem can feel borderline intractable.
When we first noticed a 34K token prompt in LangSmith, our instinct was to optimize it immediately: trim the documentation, compress the examples, cache aggressively. But a single trace doesn't tell you if that's a typical request or an outlier. By aggregating across 100+ LLM runs, we discovered the real story: 11% of runs exceeded 20K tokens, but 37% used fewer than 5K. The 34K prompt wasn't the real problem. It was the repeated 20K+ token runs that produced only 21 completion tokens each. Single-trace analysis would have sent us optimizing the wrong thing.
That experience made one thing clear: manually sifting through hundreds of traces to find these patterns isn't a viable workflow. We needed a way to ingest traces in bulk, extract structured signals from messy semi-structured data, and ask questions across hundreds of runs at once. So we pointed Deductive AI at our LangSmith traces.
Lessons from Optimizing Production Agents with Deductive
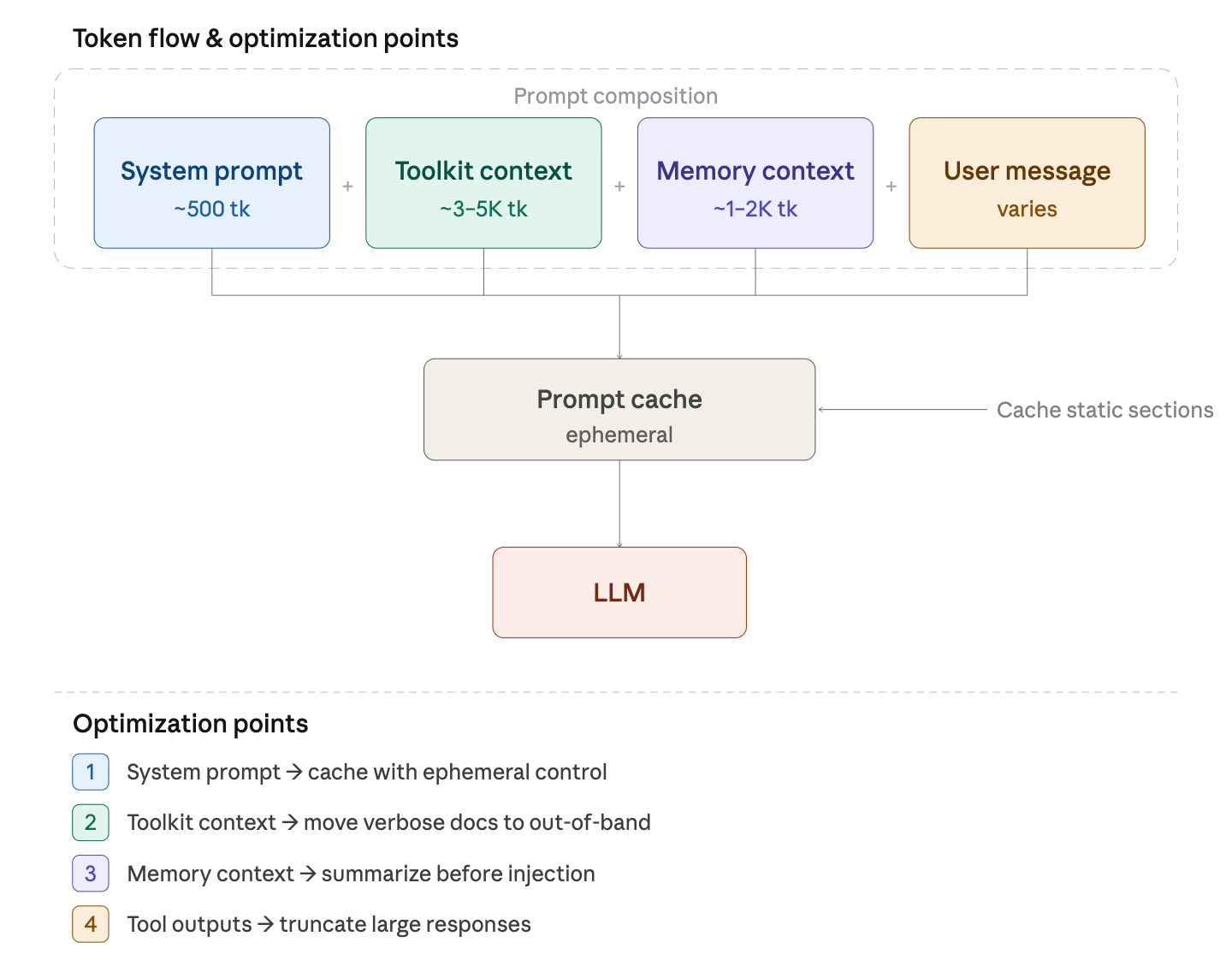
Expensive Calls Deserve Cheap Guards
Our most surprising finding was a pattern we called "wasteful optimization runs." Every time our customer’s AI agent completed a task successfully, the system would automatically send a full transcript of everything the agent did (typically 10,000 to 22,000 tokens) to a second AI model. That model's job was to review the transcript, extract any lessons learned, and save them for next time. The problem? When the agent had executed cleanly with no mistakes, there was nothing to learn. The reviewing model would read through the entire transcript, find nothing useful, and immediately return an empty response, resulting in just 21 tokens of output after processing 22,000 tokens of input. Across just six of these no-op runs, our customer burned through 97,000 tokens for literally zero useful output. The fix was simple: before sending the transcript to the reviewer, check whether it contains any error signals (failed commands, retries). If the execution was clean, skip the review entirely.
Use the Big Hammer Carefully
As an agent grows in complexity, it becomes increasingly difficult to reason about which steps actually require deep thinking and which are essentially binary decisions. When you're writing the code, every step feels important, but a routing decision ("should I query Source A or Source B?") doesn't need the same horsepower as synthesizing a final answer from large amounts of evidence. By constructing a comprehensive work graph from our LangSmith traces, Deductive identified steps that were using our most expensive model for what amounted to flow control. Swapping those to a lighter model had no measurable impact on quality but meaningfully reduced cost per run.
The Cost of "Just In Case" Documentation
By analyzing the customer’s longest prompts in LangSmith, we discovered that troubleshooting documentation was consuming 3-5K tokens per request, even for simple queries. Every call to our customer’s Executor Agent included verbose troubleshooting guides, error recovery patterns, and detailed examples baked directly into the prompt. The model rarely needed any of it, yet it was always there, always billed. Moving that documentation to an "out-of-band" reference field and letting the model pull it in just-in-time, only when it actually encountered an error, reduced our per-request token footprint by 20-30%.
What This Means for Your Agents
Wasteful no-op calls, over-powered routing steps, and always-on documentation aren't unique to this customer. These antipatterns show up across most production agents we've analyzed, and they're hard to detect and quantify until you start looking across runs rather than within them.
At Deductive AI, we believe we’re heading towards a meaningful shift in the way the observability world currently handles LLM traces. Right now most teams are still in the "open a trace, poke around" phase. But as agents grow more complex and API costs compound, the teams that pull ahead will be the ones treating their trace data as a queryable dataset rather than a collection of individual logs.
If you're already using LangSmith and wondering where your token budget is actually going, try Deductive AI. Point it at your traces and start seeing the haystack, rather than the needle you happened to pull out.






